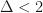Pranjal, Moses, Ravishankar, Soledad, Rachel, and myself just uploaded our new paper “Relax, no need to round: Integrality of clustering formulation” to the arxiv and I would like to briefly describe some of the results here.
The problem we consider is that of clustering a point cloud in 
Unfortunately, these problems are in general NP-hard and so it is common to rely on heuristics of approximation algorithms. While many of the popular iterative heuristics (such as the classical k-means algorithm) are incredibly efficient they do, oftentimes, get stuck in local minima and, worst of all, after running the algorithm it is, in general, hard to determine whether the computed solution is a local or global optima.
On the other hand, convex relaxations operate by enlarging the search space (to make the problem easy) and so the computed solution might not be an admissible solution of the original problem. In this case, it is common to apply a rounding procedure to construct a solution to the original problem that, while possibly suboptimal, has performance guarantees.
The remarkable thing happens when, for whatever reason, the solution to the enlarged problem is also admissible in the original problem, as in that case, not only the algorithm computes the optimal solution to the original problem but also produces a peace-of-mind certificate of its optimality. For this reason, I believe that understanding when this phenomenon happens is an important problem, and have talked about it here.
In this paper we attempt to understand when this phenomenon happens for convex relaxations of k-means and k-medians. In particular, we are interested in comparing different convex relaxations for these clustering objectives not from the traditional perspective of approximation ratio but instead from their ability to exactly recover the planted cluster structure on certain generative models of point clouds.
Inspired by earlier work of Rachel and Abhinav Nellore, we consider a simple setting: The point cloud (intended to have a planted k clustering) is generated by taking k unit radius spheres in
In order to hope to recover the planted clustering we need the minimum distance between the centers of the spheres 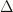
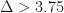
In this paper we show that, for arbitrarily large n, a linear programming relaxation of a certain k-medians objective is able to recover the spheres for 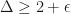
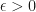
We also investigate convex relaxations for a k-means objective. Interestingly, the natural linear programming relaxation works for 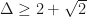
Although it is impossible to recover the cluster structure for