In this post I am going to talk about a classical mathematical dimension-reduction tool (from the 80’s) that I really like, the Johnson-Lindenstrauss Lemma, and a faster version of it, more recently developed.
Suppose one has  points,
points,  , in
, in 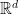 (with
(with  very large). If
very large). If  , since the points have to lie in a subspace of dimension it is clear that one can consider the projection
, since the points have to lie in a subspace of dimension it is clear that one can consider the projection  of the points to that subspace and keep the whole geometry of
of the points to that subspace and keep the whole geometry of  . In particular, for every
. In particular, for every  and
and 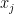 ,
, 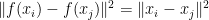 , meaning that
, meaning that  is an isometry in .
is an isometry in .
Let’s say that we allow a bit of distortion, we are looking for 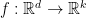 that is an
that is an  isometry, meaning that
isometry, meaning that

Can we do better than  ?
?
In 1984, Johnson and Lindenstrauss showed a remarkable Lemma that answers this question positively.
Theorem 1 (Johnson-Lindenstrauss Lemma) For any  and any integer , let
and any integer , let  such that
such that
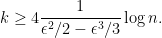
Then, for any set of points in , there is a linear map 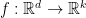 that is an isometry for . Furthermore, this map can be found in randomized polynomial time.
that is an isometry for . Furthermore, this map can be found in randomized polynomial time.
I going to show below an elementary proof (borrowed from this paper).
Before the proof, we need a few concentration of measure bounds, I will omit the proof of those but they are available in the same paper and their proof relies on essentially the same ideas as used to show Hoefding bounds.
Lemma 2 Let  iid standard Gaussian random variables and
iid standard Gaussian random variables and  . Let
. Let 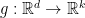 be the projection into the first coordinates and
be the projection into the first coordinates and  and
and 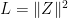 , it is clear that
, it is clear that 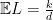 . In fact,
. In fact,  is very concentrated around its mean
is very concentrated around its mean
Proof of the Johnson-Lindenstrauss Lemma:
We’ll start by showing that, given a pair 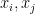 , a projection onto a random subspace of dimension will satisfy (after appropriate scaling) property (1) with high probability. WLOG, we can assume that
, a projection onto a random subspace of dimension will satisfy (after appropriate scaling) property (1) with high probability. WLOG, we can assume that 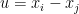 is unit norm. Understanding what is the norm of the projection of
is unit norm. Understanding what is the norm of the projection of  on a random subspace of dimension is the same as understanding the norm of the projection of a (uniformly) random point on
on a random subspace of dimension is the same as understanding the norm of the projection of a (uniformly) random point on 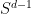 (the unit sphere in ) on a specific
(the unit sphere in ) on a specific  dimensional subspace, let’s say the one generated by the first canonical basis vectors. This means that we are interested in the distribution of the norm of the first entries of a random vector drawn from the uniform distribution over — this distribution is the same as taking a standard gaussian vector in and normalizing it to the unit sphere.
dimensional subspace, let’s say the one generated by the first canonical basis vectors. This means that we are interested in the distribution of the norm of the first entries of a random vector drawn from the uniform distribution over — this distribution is the same as taking a standard gaussian vector in and normalizing it to the unit sphere.
Let be the projection on a random dimensional subspace and let defined as  . Then (by the above discussion), given a pair of distinct and ,
. Then (by the above discussion), given a pair of distinct and ,  has the same distribution as
has the same distribution as  , as defined in Lemma~2. Using Lemma~2, we have, given a pair ,
, as defined in Lemma~2. Using Lemma~2, we have, given a pair ,
![\displaystyle \mathrm{Prob}\left[ \frac{\|f(x_i)-f(x_j)\|^2}{\|x_i-x_j\|^2} \leq (1-\epsilon) \right] \leq \exp\left( \frac{k}2(1-(1-\epsilon) +\log(1-\epsilon)) \right),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7BProb%7D%5Cleft%5B+%5Cfrac%7B%5C%7Cf%28x_i%29-f%28x_j%29%5C%7C%5E2%7D%7B%5C%7Cx_i-x_j%5C%7C%5E2%7D+%5Cleq+%281-%5Cepsilon%29+%5Cright%5D+%5Cleq+%5Cexp%5Cleft%28+%5Cfrac%7Bk%7D2%281-%281-%5Cepsilon%29+%2B%5Clog%281-%5Cepsilon%29%29+%5Cright%29%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
since, for 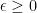 ,
,  we have
we have
![\displaystyle \begin{array}{rcl} \mathrm{Prob}\left[ \frac{\|f(x_i)-f(x_j)\|^2}{\|x_i-x_j\|^2} \leq (1-\epsilon) \right] & \leq & \exp\left( -\frac{k\epsilon^2}4 \right) \\ & \leq & \exp\left( -2\log n \right) = \frac1{n^2}. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cmathrm%7BProb%7D%5Cleft%5B+%5Cfrac%7B%5C%7Cf%28x_i%29-f%28x_j%29%5C%7C%5E2%7D%7B%5C%7Cx_i-x_j%5C%7C%5E2%7D+%5Cleq+%281-%5Cepsilon%29+%5Cright%5D+%26+%5Cleq+%26+%5Cexp%5Cleft%28+-%5Cfrac%7Bk%5Cepsilon%5E2%7D4+%5Cright%29+%5C%5C+%26+%5Cleq+%26+%5Cexp%5Cleft%28+-2%5Clog+n+%5Cright%29+%3D+%5Cfrac1%7Bn%5E2%7D.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
On the other hand,
![\displaystyle \mathrm{Prob}\left[ \frac{\|f(x_i)-f(x_j)\|^2}{\|x_i-x_j\|^2} \geq (1+\epsilon) \right] \leq \exp\left( \frac{k}2(1-(1+\epsilon) +\log(1+\epsilon)) \right).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7BProb%7D%5Cleft%5B+%5Cfrac%7B%5C%7Cf%28x_i%29-f%28x_j%29%5C%7C%5E2%7D%7B%5C%7Cx_i-x_j%5C%7C%5E2%7D+%5Cgeq+%281%2B%5Cepsilon%29+%5Cright%5D+%5Cleq+%5Cexp%5Cleft%28+%5Cfrac%7Bk%7D2%281-%281%2B%5Cepsilon%29+%2B%5Clog%281%2B%5Cepsilon%29%29+%5Cright%29.+&bg=ffffff&fg=000000&s=0&c=20201002)
since, for ,  we have
we have
![\displaystyle \begin{array}{rcl} \mathrm{Prob}\left[ \frac{\|f(x_i)-f(x_j)\|^2}{\|x_i-x_j\|^2} \leq (1-\epsilon) \right] & \leq & \exp\left( -\frac{k\left(\epsilon^2 - 2\epsilon^3/3\right)}4 \right) \\ & \leq & \exp\left( -2\log n \right) = \frac1{n^2}. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cmathrm%7BProb%7D%5Cleft%5B+%5Cfrac%7B%5C%7Cf%28x_i%29-f%28x_j%29%5C%7C%5E2%7D%7B%5C%7Cx_i-x_j%5C%7C%5E2%7D+%5Cleq+%281-%5Cepsilon%29+%5Cright%5D+%26+%5Cleq+%26+%5Cexp%5Cleft%28+-%5Cfrac%7Bk%5Cleft%28%5Cepsilon%5E2+-+2%5Cepsilon%5E3%2F3%5Cright%29%7D4+%5Cright%29+%5C%5C+%26+%5Cleq+%26+%5Cexp%5Cleft%28+-2%5Clog+n+%5Cright%29+%3D+%5Cfrac1%7Bn%5E2%7D.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
This means that (by union bound)
![\displaystyle \mathrm{Prob}\left[ \frac{\|f(x_i)-f(x_j)\|^2}{\|x_i-x_j\|^2} \notin [1-\epsilon,1+\epsilon] \right] \leq \frac2{n^2}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7BProb%7D%5Cleft%5B+%5Cfrac%7B%5C%7Cf%28x_i%29-f%28x_j%29%5C%7C%5E2%7D%7B%5C%7Cx_i-x_j%5C%7C%5E2%7D+%5Cnotin+%5B1-%5Cepsilon%2C1%2B%5Cepsilon%5D+%5Cright%5D+%5Cleq+%5Cfrac2%7Bn%5E2%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
Since there exist  such pairs, again, a simple union bound gives
such pairs, again, a simple union bound gives
![\displaystyle \mathrm{Prob}\left[ \exists_{i,j}:\frac{\|f(x_i)-f(x_j)\|^2}{\|x_i-x_j\|^2} \notin [1-\epsilon,1+\epsilon] \right] \leq \frac2{n^2} = 1-\frac1n.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7BProb%7D%5Cleft%5B+%5Cexists_%7Bi%2Cj%7D%3A%5Cfrac%7B%5C%7Cf%28x_i%29-f%28x_j%29%5C%7C%5E2%7D%7B%5C%7Cx_i-x_j%5C%7C%5E2%7D+%5Cnotin+%5B1-%5Cepsilon%2C1%2B%5Cepsilon%5D+%5Cright%5D+%5Cleq+%5Cfrac2%7Bn%5E2%7D+%3D+1-%5Cfrac1n.+&bg=ffffff&fg=000000&s=0&c=20201002)
This means that chosen as a properly scaled projection onto a random dimensional subspace is an isometry on (see (1)) with probability at least  . This means we can achieve any desirable constant probability of success by trying
. This means we can achieve any desirable constant probability of success by trying  such random projections, meaning we can find an isometry in randomized polynomial time.
such random projections, meaning we can find an isometry in randomized polynomial time.
In fact, by considering slightly larger, we can get a good projection on the first random attempt with very good confidence. It’s trivial to adapt the proof above to obtain:
Lemma 3 For any ,  , and for any integer , let such that
, and for any integer , let such that

Then, for any set of points in , take to a suitably scaled projection on a random subspace of dimension , then is an isometry for (see (1)) with probability at least 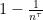 .
.
Lemma 3 is quite remarkable. Think about the situation where we are given a high-dimensional data set in a streaming fashion — meaning that we get each data point at a time, consecutively. To run a dimension-reduction technique like Principal component analysis or Diffusion maps we would need to wait until we received the last data point and then compute the dimension reduction map (both PCA and Diffusion Maps are, in some sense, data adaptive). Using Lemma 3 you can just choose a projection at random in the beginning of the process (all we need to have is an estimate of the 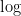 of the size of the data set) and just map each point using this projection matrix which can be done online — we don’t need to see the next point to compute the projection of the current data point. Lemma 3 ensures that this (seemingly naive) procedure will, with high probably, not distort the data by more than
of the size of the data set) and just map each point using this projection matrix which can be done online — we don’t need to see the next point to compute the projection of the current data point. Lemma 3 ensures that this (seemingly naive) procedure will, with high probably, not distort the data by more than  .
.
Fast Johnson-Lindenstrauss
In what follows I will very briefly and very intuitively explain an interesting idea behind a faster version of Johnson-Lindenstrauss proposed in this very nice paper.
Let’s continue thinking about the high-dimensional streaming data. After we draw the random projection matrix, say  , for each data point
, for each data point  , we still have to compute
, we still have to compute  which, since has
which, since has 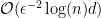 entries, has a computational cost of . In some applications this might be too expensive, can one do better?
entries, has a computational cost of . In some applications this might be too expensive, can one do better?
It turns out that there is no hope of (significantly) reducing the number of rows (see this paper of Noga Alon). The only hope seems to be to speed up the matrix-vector multiplication. If we were able to construct a sparse matrix then we would definitely speed up the computation of . Unfortunately, one can show that a sparse matrix will distort sparse vectors, so if your data set contains sparse vectors will fail. Another option would be to exploit the Fast Fourier Transform and compute the Fourier Transform of (which takes 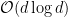 time) and then multiply the
time) and then multiply the  of by a sparse matrix.. this will again not work because the vector might have sparse Fourier Transform.
of by a sparse matrix.. this will again not work because the vector might have sparse Fourier Transform.
The solution comes from leveraging a type of uncertainty principle — not both and the Fourier Transform of can be sparse. The idea is that if, before one takes the Fourier Transform of , one flips (randomly) the signs of , then the probably of obtaining a sparse vector is very small so a sparse matrix can be used for projection. In a nutshell the algorithm has be a matrix of the form  , where
, where  is a diagonal matrix that flips the signs of the vector randomly,
is a diagonal matrix that flips the signs of the vector randomly,  is a Fourier Transform and
is a Fourier Transform and  a sparse matrix. This method was proposed and analysed here and, roughly speaking, achieves a complexity of , instead of the classical
a sparse matrix. This method was proposed and analysed here and, roughly speaking, achieves a complexity of , instead of the classical  .
.
,
,
![\displaystyle \mathrm{Prob}\left[ L \leq \beta \frac{k}d\right] \leq \exp\left( \frac{k}2(1-\beta +\log\beta) \right).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7BProb%7D%5Cleft%5B+L+%5Cleq+%5Cbeta+%5Cfrac%7Bk%7Dd%5Cright%5D+%5Cleq+%5Cexp%5Cleft%28+%5Cfrac%7Bk%7D2%281-%5Cbeta+%2B%5Clog%5Cbeta%29+%5Cright%29.+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathrm{Prob}\left[ L \geq \beta \frac{k}d\right] \leq \exp\left( \frac{k}2(1-\beta +\log\beta) \right).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7BProb%7D%5Cleft%5B+L+%5Cgeq+%5Cbeta+%5Cfrac%7Bk%7Dd%5Cright%5D+%5Cleq+%5Cexp%5Cleft%28+%5Cfrac%7Bk%7D2%281-%5Cbeta+%2B%5Clog%5Cbeta%29+%5Cright%29.+&bg=ffffff&fg=000000&s=0&c=20201002)

Reblogged this on arasasaad.
Hi,
In JL lemma proof, I was wodering what exactly is the value of n? For the two inequalities, different expressions were substituted for n. How is this possible?
Hi Sri Hari,
Thanks for you question.
n is the number of points that one is trying to project. I am not sure I understand what do you mean by different expressions, can you point them out for me on the text?
Thanks!
Best,
Afonso