I started thinking about the problem of building deterministic RIP matrices 3 years ago, when, as a first year graduate student at Princeton, I was sharing an office with Dustin Mixon. I am probably not exaggerating much by saying that Dustin spend a big part of his PhD obsessed with this problem, and mathematical obsessions (although not necessarily mathematical diseases), are somewhat contagious. Since then I have (together with Dustin and others) intermittently thought about RIP matrices and have had some successes (a promising construction, hardness results for certifying this property and, more recently, a construction conditioned on a Number Theory conjecture – a paper should appear soon). Still, we have so far failed to achieve the goal: a deterministic construction that compares with random constructions.
I am not going to go into the problem (you can read all about it in: Terry Tao’s blog, our paper, Dustin’s new blog post, Dustin’s old blog post, etc). The objective is to increase the exponent on the sparsity parameter. It turns out that, due to the techniques normally used, it is particularly difficult to increase the exponent beyond 

In fact, the only deterministic construction known to break the square-root bottleneck is the know proposed in the breakthrough paper
J. Bourgain et al., Explicit constructions of RIP matrices and related problems
Although a breakthrough result, this paper had a disappointing impact in the community and, to the best of my knowledge, no further progress on the problem has since been made using similar techniques (in over 3 years time). In my opinion, the reason for this is perhaps twofold: 1) the techniques used are involved and rely heavily on Additive Combinatorics (an area that most people interested in RIP matrices are not very familiar with) and 2) the gain over the square root bottleneck is modest: the exponent obtained is 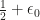

A few days ago, Dustin called me saying that he was carefully going through Bourgain et al.’s paper and was wondering how far their analysis can be pushed to yield a larger 
The main purpose of the post is accomplished: Advertising the new wiki page. In the rest of this post, I’ll introduce a piece of notation that I think will be helpful and make my own baby step on increasing
The 
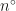
In many occasions in the analysis in Bourgain et al.’s paper there is the need to have numbers (most often, appearing in exponents) being larger (or smaller) than a given integer (or real number), say 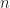
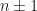


for an arbitrarily small (fixed)
for an arbitrarily small (fixed)
A baby step in the path to a larger
On page 174 of this version of the paper (two equations above (7.1.) in the proof of Lemma 10) the inequality can be made sharper:
Due to the size of 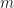

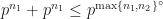




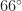

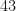
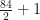
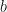
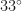

.
I am looking forward to see how far we can push this value.

I think you mean the 60 is later _divided_ by 2.
[Corrected, thanks. B.]