This upcoming fall, I am teaching a special topics course at the Math Department in MIT, called Topics in Mathematics of Data Science. This will be a mostly self-contained research-oriented course focusing on the theoretical aspects of algorithms that aim to extract information from data.
I have divided the content of the class in ten topics (or “lectures”), I’ll describe them below. The biggest novelty perhaps is that I have decided to present a number of open problems on each of these lectures. Given that this list of problems (and their description) may be of interest to the readers of this blog, I plan to include short versions of the lecture notes as blog posts (linking to the proper lecture notes) and include a description of a total of forty open problems over the course of ten future posts. I am hoping interesting discussions about some of these problems arise from comments on these posts!
This “post zero” serves as an announcement for the class (if you are a student at MIT, think about taking the class!) and a warm-up for the open problems, I am including two below. But first, the content of the class:
- Principal Component Analysis (PCA) and some random matrix theory that will be used to understand the performance of PCA in high dimensions, through spike models.
- Manifold Learning and Diffusion Maps: a nonlinear dimension reduction tool, alternative to PCA. Semisupervised Learning and its relations to Sobolev Embedding Theorem.
- Spectral Clustering and a guarantee for its performance: Cheeger’s inequality.
- Concentration of Measure and tail bounds in probability, both for scalar variables and matrix variables.
- Dimension reduction through Johnson-Lindenstrauss Lemma and Gordon’s Escape Through a Mesh Theorem.
- Compressed Sensing/Sparse Recovery, Matrix Completion, etc. If time permits, I will present Number Theory inspired constructions of measurement matrices.
- Group Testing. Here we will use combinatorial tools to establish lower bounds on testing procedures and, if there is time, I might give a crash course on Error-correcting codes and show a use of them in group testing.
- Approximation algorithms in Theoretical Computer Science and the Max-Cut problem.
- Clustering on random graphs: Stochastic Block Model. Basics of duality in optimization.
- Synchronization, inverse problems on graphs, and estimation of unknown variables from pairwise ratios on compact groups.
Now to the open problems!
Open Problem 0.1.
Komlós Conjecture (see here for description on lecture notes)
We start with a fascinating problem in Discrepancy Theory.
Given
, let
denote the infimum over all real numbers such that: for all set of
satisfying
, there exist signs
such that
There exists a universal constant
such that
for all
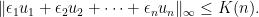
An early reference for this conjecture is a book by Joel Spencer. This conjecture is tightly connected to Spencer’s famous Six Standard Deviations Suffice Theorem. Later in the course we will study semidefinite programming relaxations, recently it was shown that a certain semidefinite relaxation of this conjecture holds, the same paper also has a good accounting of partial progress on the conjecture.
Open Problem 0.2.
Matrix AM-GM inequality (see here for description on lecture notes)
We move now to an interesting generalization of arithmetic-geometric means inequality, which has applications on understanding the difference in performance of with- versus without-replacement sampling in certain randomized algorithms (see this paper by Ben Recht and Christopher Re).
For any collection of
positive semidefinite matrices
, the following is true:
(a)
and
(b)
where
denotes the group of permutations of
the spectral norm.
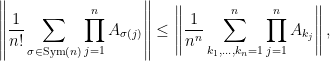
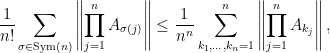
Morally, these conjectures state that products of matrices with repetitions are larger than without. For more details on the motivations of these conjecture (and their formulations) see this paper for conjecture (a) and this commentary by John Duchi for conjecture (b).
Recently these conjectures have been solved for the particular case of 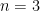

There is a 2020 preprint that says the matrix AM-GM inequality is false for general n with the first counterexample for n=5, one of the authors was interviewed on quanta magazine and mentions the paper on passing, I don’t work on this stuff but recalled reading this blog post from a mathoverflow answer, couldn’t find if you mentioned that preprint on some another blog post later so I’m leaving this message just in case, best regards.
* https://arxiv.org/abs/2006.01510
* https://www.quantamagazine.org/an-applied-mathematician-strengthens-ai-with-pure-math-20230301/
* https://mathoverflow.net/questions/342966/is-data-science-mathematically-interesting